Many enterprises face the same problem every day: how to handle the ever-growing piles of hard copy archives and gigabytes of exchanged documents in various raster formats, often representing unorganized and unstructured data. In order to use any of such data, one has to classify it first. For example, accounting documents can be divided into contracts, invoices, acceptance reports and many more. Network technical documentation can be divided into design maps, network acceptance protocols, surveying protocols, network failure protocols, station failure protocols, technical inspection cards,… etc. However, the classification process, if done manually, can be time-consuming, costly and frustrating for everyone involved. Can the solution to this problem come from Artificial Intelligence? We decided to test it and applied machine learning techniques to classify and sort out various document types as a part of the currently ongoing R&D project GlobIQ.
Experiments with classifying
Our experiment involved using a naive Bayesian classifier in a supervised learning mode in order to classify the project documentation.
Supervised text classification involves automatic assigning texts to a set of predefined classes, also called categories. A document may belong to a single class (single label classification) or multiple classes (multi-label classification), depending on the subjective evaluation of the set. A variant of the single label classification is the so-called binary classification, in which each document is assigned to a set or its complement.
Its steps were as follows:
We used the following classifiers from the scikit-learn library:
- Random Forest Classifier
- Linear Support Vector Classification
- Multinomial Naive Bayes Classifier
- Logistic Regression
To evaluate the classifiers, we used the same training set (automatically divided into a training subset and a test subset) of 470 documents with a known category. As the basic measure of the classifiers’ performance we used the parameter “accuracy”. This parameter is the ratio of the number of correctly predicted values to the total number of values in the test set.
The results for particular classifiers were as follows:
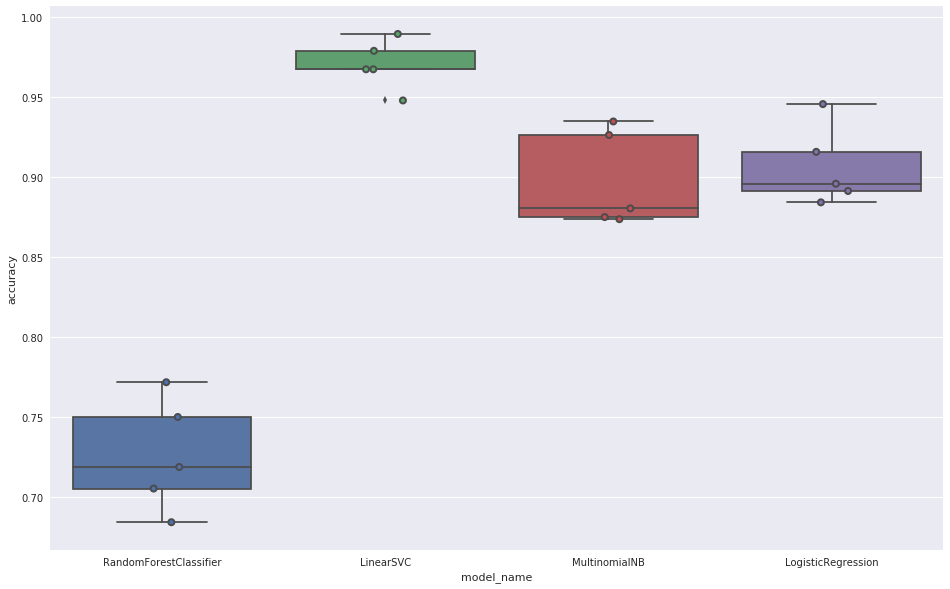
The best result (0.975) was achieved by a classifier using LinearSVC and was used later in the experiment.
- We used the best classifier found – LinearSVC – to simulate the production classification of a set of 6272 PDF documents with scans (about 24000 A4 pages). The workflow was as follows:
- extracting JPG files from the PDF files
- using OCR to retrieve plain text from the JPG file
- using the classifier and predicting the document category
- comparing the predicted category with the category determined by the operator (correct one)
The experiment results were as follows:
| Category | Documents in the category | Incorrect predictions | Accuracy | Notes |
| 1 | 2,050 | 329 | 84.0% | Low quality scans |
| 2 | 342 | 1 | 99.7% | |
| 3 | 2,340 | 13 | 99.4% | |
| 4 | 0 | 0 | - | No documents in the production set |
| 5 | 1,539 | 13 | 99.2% | |
| Total | 6,272 | 357 | - |
Conclusions from the experiment
The achieved accuracy of document categorization was very high – for 3 categories it was above 99%. Only for one category, the accuracy was 84%. The classification of large volumes of documents (10,000 – 20,000) is completed within a few minutes. We estimate that manual viewing and classification of 10,000 documents would take about 10-20 days. The experiment proves that AI methods & tools, including algorithms used by GlobIQ, can be very useful in document classification.
If you’re interested in more details about GlobIQ or our other Artificial Intelligence and Machine Learning solutions, click here or reach out to us – we will be happy to help.